Solving Basic Problems
Now that we have set up the general framework of problems of interest, let's think about how to solve them. We begin with a standard example:
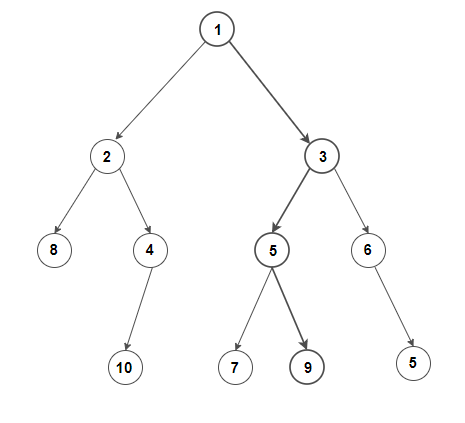
We could brute force this problem by looking at every path, but there is a far better approach. Consider the following pseudo-code
Input: A directed non-negative weighted tree T
for node in reverse_topological_sort T
if node.isLeaf:
node.path = [node]
else:
max_child = max(node.children on weight)
node.weight += max_child.weight
node.path = max_child.path + [node]
Output: root.path
This algorithm is an example of backwards recursion. The idea is that at any particular node, we can treat it as the root node, find the optimal path from that node onwards, and treat the maximum sum as the weight of the node. Thus, we can recurse backwards until we reach the root node. Amazingly, this algorithm only involves a maximum of two calls to any particular node's weights (an update and a read), vs the brute force method might call a particular node an arbitrarily large number of times.
This is a classic algorithm which appears in most algorithm textbooks, but can be generalized into an algorithm for solving general basic problems.
The Dynamic Programming Algorithm
In the example above, we saw how solving the path problem backwards helped avoid the computational complexity of the brute force approach. Let's generalize our intuition for why that process worked.
This result is useful since it now allows us to define the solution to the basic problem generally
Notice that \(V_k\) is the direct analog of weight in the example and \(\mu_k\) the direct analog of path. We often call the set of \(V_k\)s the Bellman surface of the basic problem
To see the computational complexity of the dynamic programming algorithm, note that we have to compute all \(V_k\)s, and then \(n\) more expected value computations to generate the optimal policy. Assuming there are \(n\) time steps, no more than \(m\) valid states at any time, and no more than \(c\) valid actions at any time, the maximal number of \(V_k\) terms to be computed is \(n\cdot m\cdot c\).
Thus, an upper bound for the computational complexity of the algorithm is compute \(nmc+n\) expected values. This is linear in state space size, action space size, and time.
The beauty of this algorithm is that most additional complexities (time delays, partial information, etc) can be easily dealt with by expanding the state space. However, in practice, this can lead to enormous state spaces which aren't great to work with. We'll talk about how to deal with that in the next post.